Semantic reconstruction of continuous language from non-invasive brain recordings
2023, Nature Neuroscience
https://www.nature.com/articles/s41593-023-01304-9

Abstract
- fMRI로 기록된 뇌 반응에서 연속적인 언어를 재구성할 수 있는 비침습적 디코더에 대한 소개
- perceived speech, imagined speech, perceived movie, 등 다양한 인지 과정을 정확하게 표현하는 단어 시퀀스를 생성
- 대뇌 피질의 여러 영역에서 테스트한 결과, 여러 영역의 언어를 디코딩할 수 있는 것으로 나타남
- mental privacy: 훈련과 적용 모두 피험자의 협조가 필요하며, 사용자의 동의 없이는 BCI를 사용할 수 없었음
Goal
Multi-head Self-attention GPT-1 모델을 사용해 perceived 및 imagined speech를 할 때, 발현되는 뇌 신호로부터 정보를 재구성
Motivation
- 기존의 BCI는 특정 의료 분야로 침습적 방법에 의존하고 있었습니다.
하지만, 침습적인 특징으로 수술과 관련된 위험과 복잡성으로 인해 광범위하게 사용하기에 어려움이 존재합니다. - 이전의 비침습적 언어는 디코더의 작은 단어나 구문으로 제한되어 있어 복잡한 언어의 처리 및 이해와 관련된 복잡한 신경 패턴을 포착할 수 없었습니다.
Contribution
- fMRI로 기록된 피질 의미 표현에서 연속적인 언어를 재구성할 수 있는 비침습적인 디코더 개발
- 여러 대뇌 피질 영역에서 분리된 언어 디코딩
Data
- 7명의 정상인 피험자
- fMRI 64채널
- 실험군이 없어서 블라인드 테스트 진행 안함
Data availability
Code availability
GitHub - HuthLab/semantic-decoding
Contribute to HuthLab/semantic-decoding development by creating an account on GitHub.
github.com
Model test dataset
- Perceived speech
- 5-15분 분량의 이야기를 들음 (The Moth Radio Hour, Modern Love and The Anthropocene Reviewed)
- 자극 전 후에 10초의 무음 버퍼
- Imagined speech
- 1분 분량의 이야기 상상 (모델 훈련에서 나온 5개의 Modern Love 중에서 1분 분량만)
- 피험자들은 각 세그먼트 ID(‘alpha’, ‘bravo’, ‘charlie’, ‘delta’ and ‘echo’) 학습
- 각 ID에 대한 cue를 듣고 기억에서 해당 세그먼트를 말하는 것을 상상
- 각 이야기 세그먼트는 14분 동안의 단일 fMRI에서 2번 시행
- 각 cue 후의 10초의 준비 시간
- 각 세그먼트 후 10초의 휴식 시간
- Perceived movie
- 4-6분 분량의 단편 애니메이션 영화 클립 4편 시청 (‘La Luna’ (Pixar Animation Studios), ‘Presto’ (Pixar Animation Studios), ‘Partly Cloudy’ (Pixar Animation Studios) and ‘Sintel’ (Blender Foundation))
- 소리가 거의 없는 무성 영화
- 피험자가 소리를 내지 않고서 fMRI 스캔
- 영상 전 후에 10초 동안 검은색 화면 버퍼 표시
- Multi-speaker
- 여성, 남성 화자가 들려주는 두 가지 이야기(The Moth Radio Hour)를 겹쳐서 구성한 6분짜리 자극 2번 시행
- 두 이야기의 음성 파형을 모노로 변환해 오버레이
- 여기서 사용한 이야기는 모델 train에서 제외
- 한 번은 여성 화자에 집중, 다른 한 번은 남성 화자에 집중
- 자극 전 후에 10초의 무음 버퍼
- 여성, 남성 화자가 들려주는 두 가지 이야기(The Moth Radio Hour)를 겹쳐서 구성한 6분짜리 자극 2번 시행
- Decoder resistance
- 80초 분량의 4가지 세그먼트 중 하나를 재생
- 세그먼트가 시작되기 전, 피험자에게 4가지 인지 task(‘listen’, ‘count’, ‘name’ and ‘tell’) 중 하나를 수행하라는 신호
- listen: 수동적으로 이야기의 부분을 듣기
- count: 머릿속으로 7까지 세기
- name: 머릿속으로 동물의 이름을 부르고 상상
- tell: 머릿속으로 다양한 이야기를 말하기
- 모든 cue에서 말하거나 다른 동작을 하지 않음
- 과정
- 각 task가 일부 세그먼트에서 가장 먼저 cue를 받도록 하고
- 각 task가 모든 세그먼트에서 정확히 한 번씩 cue를 받도록 균형을 맞춰서 총 16번 진행
- 8 trial로 구성된 14분짜리 fMRI 스캔을 2번 시행
- 각 trial 후 10초의 준비 시간과 10초의 휴식 시간
Methods
Language model
- 단어 시퀀스에 대한 사전 확률 분포 추정
- GPT-1 모델에서 멀티헤드 셀프어텐션을 가진 12개의 레이어를 사용했습니다.
- 레이어 중에서 중간에 있는 9번째 레이어를 사용해 각 단어와 시간 쌍에 대한 단어 시퀀스를 사용해 의미론적 특징을 추출하게 됩니다.
- 이 과정에서 새로운 벡터와 시간 쌍 목록이 나오게 되는데 새로 나온 벡터는 768차원의 의미를 가지고 있습니다.
768개의 특징 각각에 대해 4개의 지연이 있는 선형 시간 필터를 적용해 특징을 추출합니다.
Encoding model
- 언어 모델에서 얻은 특징을 사용해 인코딩 모델에서 사용하게 됩니다.
- 인코딩 모델에서는 혈중 산소 농도 신호에 가우시안 노이즈가 포함되는 가정을 하고, 의미적 특징을 예측된 뇌 신호에 맵핑합니다.
- 특징을 결합하는 가중치는 정규화 선형 회귀를 통해 결정합니다.
- T 시점에 대해 예측을 하여 앞서 언어 모델에서 말한 4개의 지연이 T+1, T+2, T+3, T+4 시점에 대해 특징을 구해 교차검정을 해 정규화 계수를 최적화해 BOLD 신호를 예측하게 됩니다.
Word Rate model
- 2초의 시간동안 예측된 단어 비율로 균등하게 나누어 단어 시간을 예측합니다.
Beam search decoder
- 각 시점에 평가되는 단어가 이전에 디코딩된 단어에 따라 달라지도록 가능한 시퀀스의 조합 공간을 검색하는 Bean search 알고리즘을 사용합니다.
- 가장 가능성이 높은 단어 시퀀스를 포함하는 빔을 유지하면서 지난 8초 동안의 단어 예측을 기반으로 가능한 연속을 예측합니다.
Results
디코딩 성능
- 자극의 의미를 정확하게 포착하고 정확한 단어와 구문 디코딩
- 다양한 언어 유사성 메트릭에서 나은 성능을 보임
대뇌피질 영역 분석
- 언어 신호를 별도로 디코딩한 결과, 두정엽-측두엽-후두엽 연합 영역과 전두엽 영역에서 각각 언어 처리를 하고 있었습니다.
Perceived speech & Imagined speech 디코딩
- 100%의 정확도로 정확하게 식별해 perceived speech와 imagined speech와 같은 작업 전반에 걸쳐 전달할 수 있었음
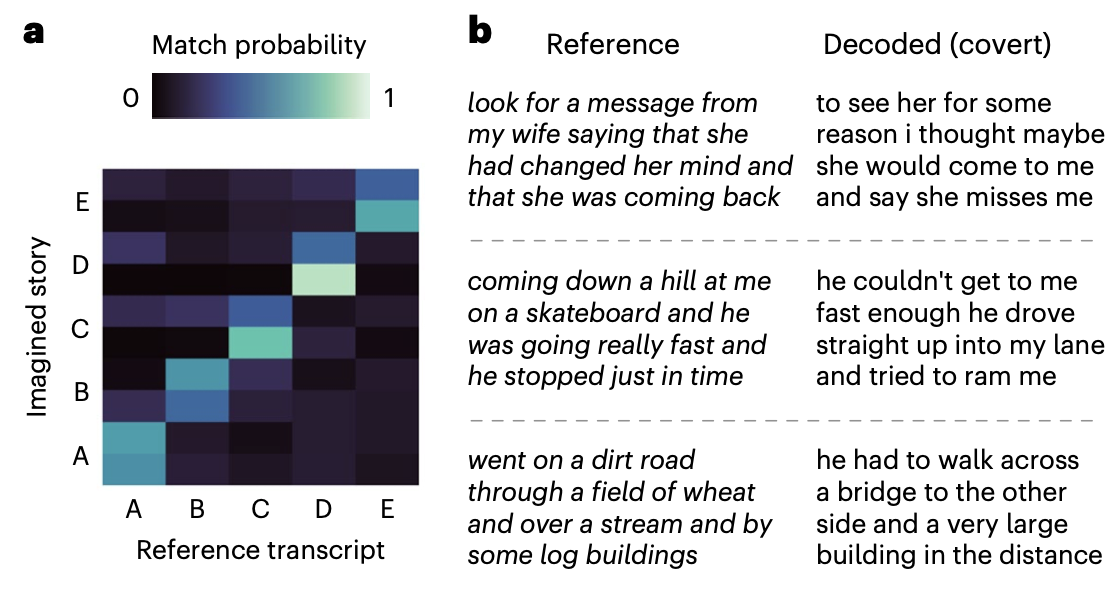
크로스 모달 디코딩
- 무성 영화 시청과 같은 비언어적 task에 대한 뇌 반응을 해석 성공
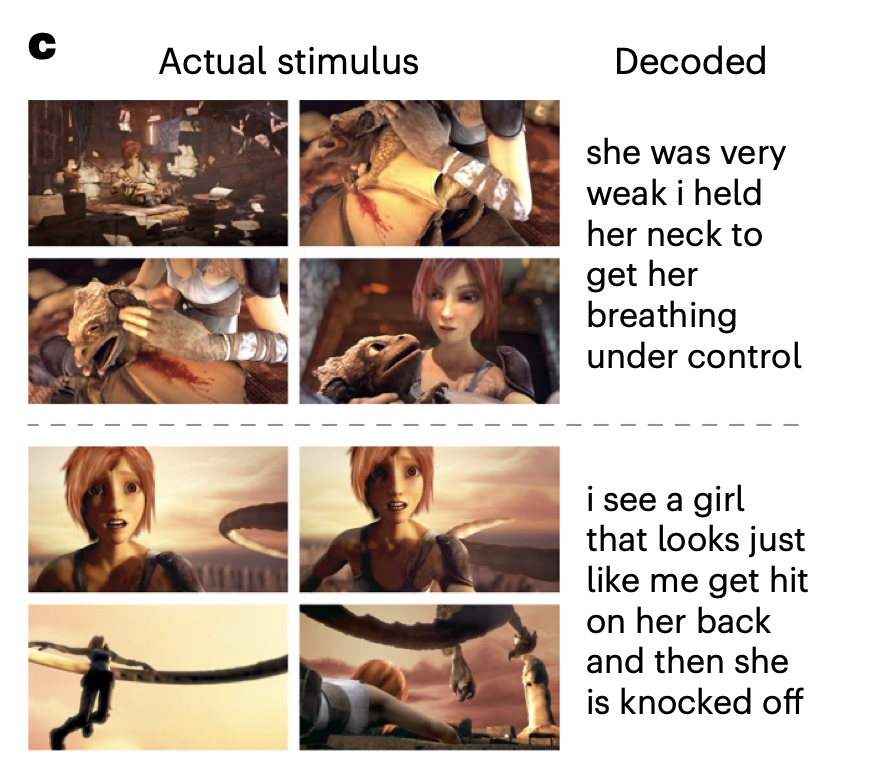
attention
- 디코딩은 주의력의 영향을 받아 피험자가 적극적으로 주의를 기울인 자극을 선택적으로 재구성
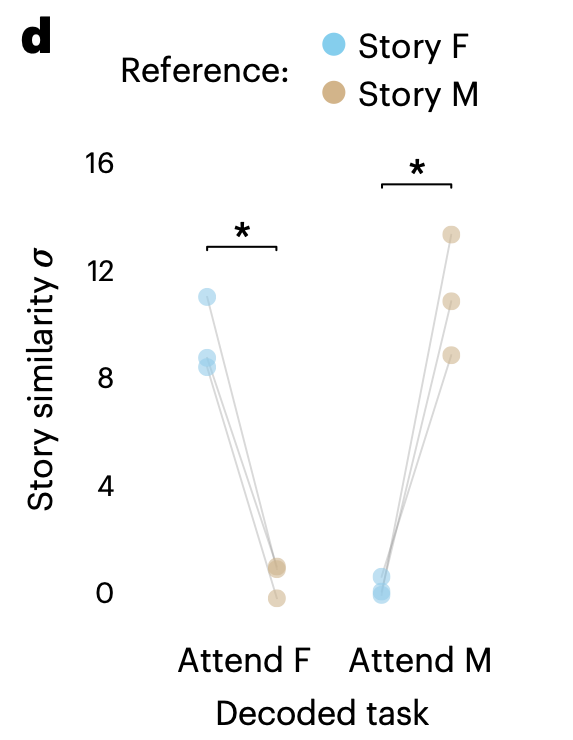
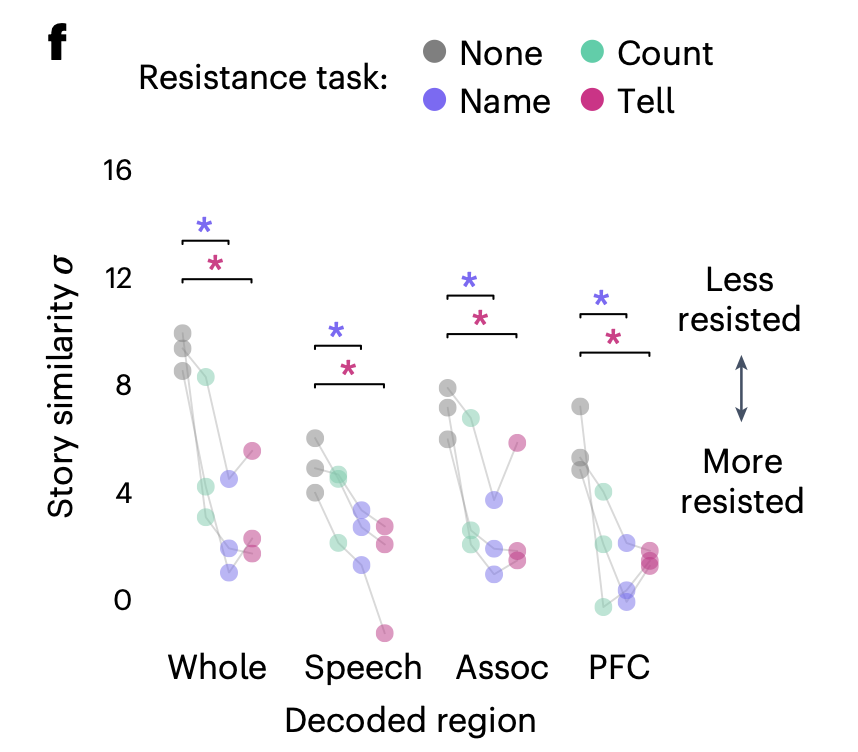
언어 유사도 테스트
- 디코더가 문자 그대로의 단어 정확도 뿐만 아니라 언어의 전반적인 의미 및 구문 내용을 디코딩하는 것을 평가했습니다.
- 평가 지표
- WER는 디코딩된 단어 시퀀스와 실제 발화 또는 의도된 단어 간의 차이를 측정하는 것으로 낮을수록 재구성된 언어에 오류가 적다는 것을 의미합니다.
- BLEU는 디코더의 출력과 참조 언어 시퀀스 세트를 비교하여 점수가 높을수록 참조 시퀀스와 일치한다는 것을 의미합니다.
- METEOR는 디코딩된 시퀀스를 참조와 비교하고 정확한 단어 일치뿐만 아니라 동의어 및 의역을 사용해 일치하는 부분을 설명하는 것으로 점수가 높을수록 의도한 언어를 재구성하는 디코더의 성능이 높다는 것을 의미합니다.
- BERTScore는 직접적인 단어의 일치뿐만 아니라 각 단어가 나타내는 문맥을 고려해 디코딩된 텍스트와 참조 텍스트 간의 의미적 유사성을 평가합니다.
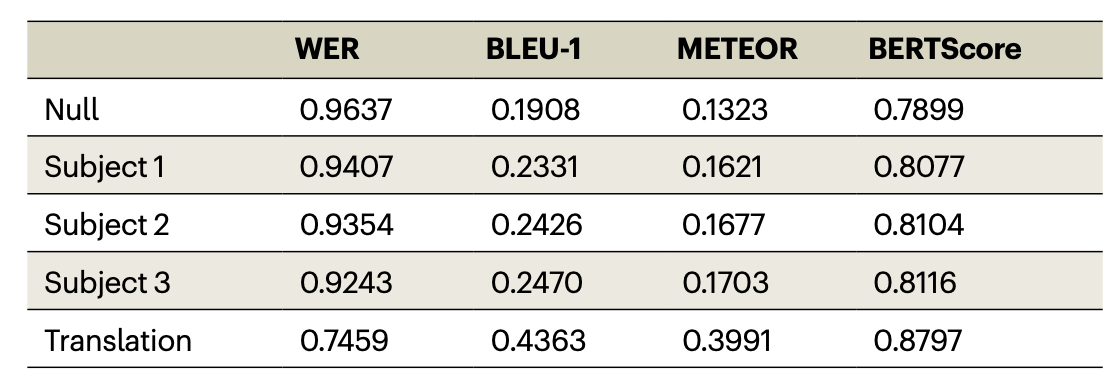
피험자 간 분석 결과
- 같은 피험자의 데이터로 훈련된 디코더와 달리, 다른 피험자의 데이터로 훈련된 디코더는 현저히 성능이 낮았다는 한계가 있었습니다.
내 생각...
아마도 fMRI를 사용해서 데이터를 측정했기 때문에, 데이터가 각 피험자의 뇌 모양에 특화되어서 다른 피험자의 데이터로 훈련된 디코더는 성능이 낮았다고 하는 것 같다. 하지만 fMRI가 아닌 다른 방식으로 한다면 subject independent를 해결할 수 있을 것이다.
semantic을 하는 연구는 대부분 공간 해상도 때문에 fMRI를 이용해 디코딩하는 거 같다. 그래서 시간 해상도가 낮다.
fMRI로 하는 연구에서는 BOLD(blood-oxygen-level-dependent)와voxel 이라는 단어가 많이 나오는거 같다.
J. Tang, A. LeBel, S. Jain, and A. Huth, “Semantic reconstruction of continuous language from non-invasive brain recordings,” Nature Neuroscience, Vol. 26, No. 5, 2023, pp. 858-866.




Comment